Contains Duplicate
문제 설명
Given an integer array nums, return true if any value appears at least twice in the array, and return false if every element is distinct.
제한 사항
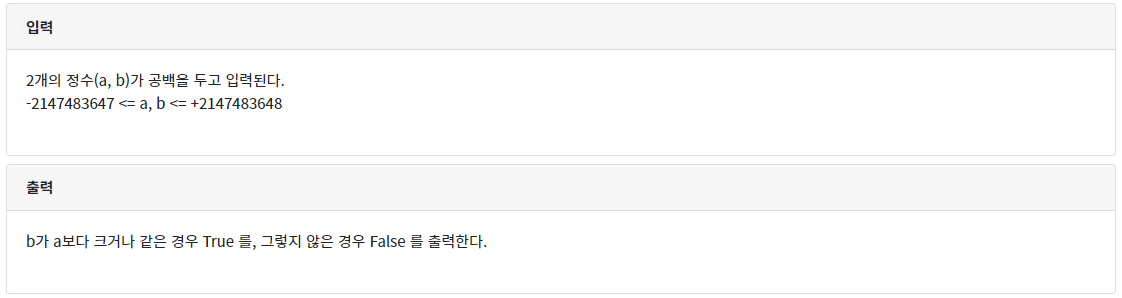
- 1 <= nums.length <= 105
- -109 <= nums[i] <= 109
입출력 예
Example 1:
Input: nums = [1,2,3,1]
Output: trueExample 2:
Input: nums = [1,2,3,4]
Output: falseExample 3:
Input: nums = [1,1,1,3,3,4,3,2,4,2]
Output: true
Python 코드
Python code
class Solution:
def containsDuplicate(self, nums: List[int]) -> bool:
return len(set(nums)) != len(nums)* 참고 링크 : https://leetcode.com/problems/contains-duplicate/discuss/1159570/Python-99.25-faster
class Solution:
def containsDuplicate(self, nums: List[int]) -> bool:
hashset = set()
for n in nums:
if n in hashset:
return True
hashset.add()
return False* 참고 링크 : https://www.youtube.com/watch?v=3OamzN90kPg
C++ 코드
C ++ code
class Solution {
public:
bool containsDuplicate(vector<int>& nums) {
unordered_map<int,bool> map;
for(size_t i = 0;i<nums.size();++i)
{
if(map[nums[i]]==true)
return true;
map[nums[i]]=true;
}
return false;
}
};* 참고 링크 : https://kkminseok.github.io/posts/leetcode_Contains_Duplicate/
출처
'코딩테스트 > Leet Code' 카테고리의 다른 글
| [Leet Code SQL] 596. Classes More Than 5 Students (0) | 2022.03.10 |
|---|---|
| [Leet Code SQL] 595. Big Countries (0) | 2022.03.04 |
| [Leet Code SQL] 184. Department Highest Salary (0) | 2022.02.11 |
| [Leet Code] 762. Prime Number of Set Bits in Binary Representation (0) | 2022.02.11 |
| [Leet Code] 342_Power of Four (0) | 2022.02.11 |