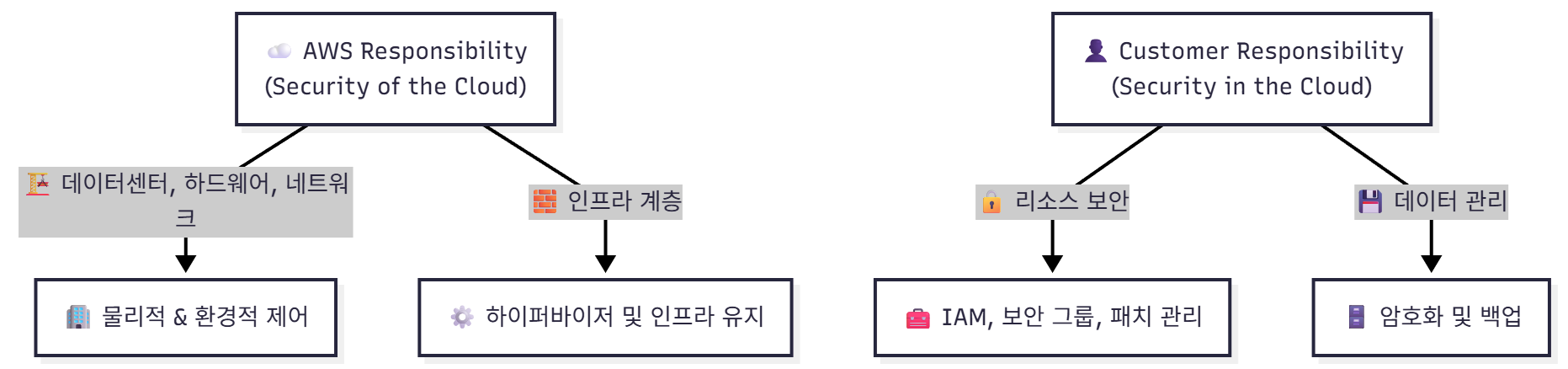
📘 Q105.
Which tasks are the customer’s responsibility, according to the AWS shared responsibility model? (Choose two)
AWS 공유 책임 모델에 따르면 고객의 책임은 무엇입니까? (2개 선택)
✅ 정답
B. Perform client-side data encryption
C. Configure IAM credentials
💡 정답 해설
| 선택지 | 설명 |
| B. Perform client-side data encryption | 고객은 데이터 암호화 방식(서버 측, 클라이언트 측, 키 관리 등) 을 직접 선택하고 설정해야 합니다. 즉, 클라이언트 측 암호화(Client-side encryption) 은 고객의 책임입니다. 🔐 |
| C. Configure IAM credentials | IAM 사용자, 그룹, 역할, 정책 설정 및 MFA(다중 인증) 활성화는 모두 고객의 책임입니다. 👤 |
❌ 오답 해설
| 보기 | 설명 | 이유 |
| A. Establish the global infrastructure | AWS의 전 세계 데이터센터, 리전, AZ 구축은 AWS가 관리합니다. | ❌ AWS 책임 |
| D. Secure edge locations | CloudFront 같은 엣지 로케이션 보안은 AWS가 담당합니다. | ❌ AWS 책임 |
| E. Patch Amazon RDS DB instances | Amazon RDS는 관리형 서비스(Managed Service) 로, DB 엔진 패치는 AWS가 수행합니다. |
❌ AWS 책임 |
🧩 시각화 요약 (Mermaid)
```mermaid
flowchart TD
A["☁️ AWS Responsibility<br>(Security of the Cloud)"] -->|🏗️ 데이터센터, 네트워크, 하드웨어| B["🏢 물리적 보안 & 글로벌 인프라"]
A --> C["🌎 리전, AZ, 엣지 로케이션 관리"]
D["👤 Customer Responsibility<br>(Security in the Cloud)"] -->|🔒 리소스 보안| E["🔑 IAM 설정, 접근 제어, 암호화"]
D -->|💾 데이터 관리| F["🗄️ 클라이언트 측 암호화, 백업, 보안 그룹 구성"]
```
💬 구성 설명
☁️ AWS Responsibility (Security of the Cloud)
- 🏗️ 데이터센터, 네트워크, 하드웨어 → 물리적 보안 및 글로벌 인프라 관리
- 🌎 리전, AZ, 엣지 로케이션 관리 → 안정적 서비스 제공을 위한 인프라 계층 운영
👤 Customer Responsibility (Security in the Cloud)
- 🔒 리소스 보안 → IAM, 접근 제어, 암호화 설정 관리
- 💾 데이터 관리 → 백업, 클라이언트 암호화, 보안 그룹 구성
✅ 핵심 정리
| 구분 | 책임 | 주체 예시 |
| Security of the Cloud | AWS | 리전, AZ, 엣지 로케이션, 하드웨어, 네트워크 |
| Security in the Cloud | 고객 | IAM, 데이터 암호화, 보안 그룹, 애플리케이션 설정 |
📗 한 줄 요약
AWS는 “클라우드의 보안”을,
고객은 “클라우드 안의 보안”을 책임진다.
즉, IAM과 데이터 암호화는 고객의 몫입니다. 🔒
📘 Q106.
A developer has been hired by a large company and needs AWS credentials.
Which are security best practices that should be followed? (Choose two)
개발자가 대기업에 새로 입사했으며 AWS 자격 증명이 필요합니다.
어떤 보안 모범 사례를 따라야 합니까? (2개 선택)
✅ 정답
A. Grant the developer access to only the AWS resources needed to perform the job.
E. Ensure the account password policy requires a minimum length.
💡 정답 해설
| A. Grant the developer access to only the AWS resources needed to perform the job. | 최소 권한의 원칙(Principle of Least Privilege) — 사용자가 자신의 업무에 필요한 최소한의 리소스에만 접근하도록 IAM 정책을 구성해야 합니다. 👤 |
| E. Ensure the account password policy requires a minimum length. | 강력한 비밀번호 정책(Password Policy) 설정은 IAM 보안의 기본입니다. 최소 길이, 숫자·특수문자 포함 등을 요구해야 합니다. 🔒 |
❌ 오답 해설
| B. Share the AWS account root user credentials with the developer. | 루트 계정은 절대 공유하지 않음. MFA를 적용하고 비상시에만 사용해야 함. | ❌ 심각한 보안 위반 |
| C. Add the developer to the administrator’s group. | 관리 권한(AdministratorAccess)은 너무 광범위함. 최소 권한 원칙에 어긋남. | ❌ 잘못된 권한 부여 |
| D. Configure password policy that prevents password changes. | 사용자가 주기적으로 비밀번호를 변경할 수 있어야 함. | ❌ 보안 유연성 결여 |
🧩 개념 정리: IAM 보안 모범 사례 (Best Practices)
| 🧱 루트 계정 최소화 | 루트 계정은 오직 결제나 초기 설정용으로만 사용 |
| 🔑 IAM 사용자/역할(Role) 사용 | 개별 IAM 사용자 생성, 필요시 역할 기반 접근 부여 |
| ⚙️ 최소 권한 부여 (Least Privilege) | 업무 수행에 꼭 필요한 권한만 부여 |
| 🔒 MFA(Multi-Factor Authentication) | 루트 계정 및 중요 IAM 사용자에 다중 인증 적용 |
| 🔐 비밀번호 정책 설정 | 최소 길이, 복잡도, 주기적 변경 등 적용 |
| 📊 CloudTrail 활성화 | 모든 IAM/API 활동 로깅 및 감사 추적 유지 |
🧠 시각 요약 (Mermaid)
```mermaid
flowchart TD
A[🔐 IAM Best Practices] --> B[🧱 Root 계정 제한 사용]
A --> C[⚙️ 최소 권한 원칙 적용]
A --> D[🔑 MFA 설정]
A --> E[📏 비밀번호 정책 설정]
A --> F[🧩 IAM Role 및 개별 사용자 생성]
```
📗 한 줄 요약
IAM 보안의 기본 원칙:
“최소 권한(Least Privilege)” + “강력한 암호 정책(Strong Password Policy)” = 안전한 AWS 계정 🔒
📘 Q128.
A company has a compute workload that is steady, predictable, and uninterruptible.
Which Amazon EC2 instance purchasing options meet these requirements MOST cost-effectively? (Choose two)
한 회사는 안정적이고 예측 가능하며 중단될 수 없는 컴퓨팅 워크로드를 가지고 있습니다.
이러한 요구사항을 가장 비용 효율적으로 충족하는 EC2 구매 옵션은 무엇입니까? (2개 선택)
✅ 정답
B. Reserved Instances
D. Savings Plans
💡 정답 해설
| B. Reserved Instances (RI) | 1년 또는 3년 약정을 통해 EC2 인스턴스를 예약 구매함으로써 On-Demand 대비 최대 72% 절감 가능 | ✔ 장기적이고 예측 가능한 워크로드에 이상적 |
| D. Savings Plans | 1년 또는 3년 약정으로 일정 금액의 컴퓨팅 사용량(commitment)을 약속하고, AWS가 자동으로 가장 저렴한 요금으로 적용 | ✔ 유연성 높음 — EC2, Fargate, Lambda에도 적용 가능 |
❌ 오답 해설
| A. On-Demand Instances | 필요할 때 즉시 사용 가능, 약정 없음 | ❌ 장기 사용 시 가장 비쌈 |
| C. Spot Instances | 미사용 EC2 용량을 경매식으로 구매, 90% 저렴 | ❌ 예측 불가, 언제든 중단 가능 — “uninterruptible” 조건에 맞지 않음 |
| E. Dedicated Hosts | 전용 물리 서버 제공 (BYOL 환경 등) | ❌ 보안·규정 준수에는 적합하지만 비용 효율성 낮음 |
🧩 비교 표 정리
| On-Demand | 없음 | 💸 0% | 매우 높음 | 일시적/불규칙적 |
| Reserved Instances (RI) | 1년 / 3년 | 💰 최대 72% | 중간 | 예측 가능, 고정된 워크로드 |
| Savings Plans | 1년 / 3년 | 💰 최대 72% | 매우 높음 | 예측 가능, 유연한 환경 |
| Spot Instances | 없음 | 💰 최대 90% | 낮음 | 비핵심, 중단 가능 작업 |
| Dedicated Hosts | 1년 / 3년 | 💰 낮음 | 제한적 | 규정 준수 / 라이선스 필요 환경 |
📈 시각 요약 (Mermaid)
```mermaid
graph TD
A[💻 워크로드 특성<br>Steady, Predictable, Uninterruptible] --> B[🏷️ Reserved Instances<br>1~3년 약정, 고정 워크로드에 적합]
A --> C[💡 Savings Plans<br>유연한 약정 기반 할인, 서비스 간 자동 적용]
B -.->|최대 72% 절감| D[💰 Cost Efficient]
C -.->|Flexible + Predictable| D
```
📗 한 줄 요약
예측 가능한 장기 워크로드에는
💡 “Reserved Instances + Savings Plans” 조합이 가장 경제적이다.
📘 Q131.
A company wants to migrate its on-premises workloads to the AWS Cloud.
The company wants to separate workloads for chargeback to different departments.
Which AWS services or features will meet these requirements? (Choose two)
회사는 온프레미스 워크로드를 AWS 클라우드로 마이그레이션하려고 합니다.
각 부서별로 워크로드를 분리하고 비용을 부서별로 배분(Chargeback)하려고 합니다.
어떤 AWS 서비스/기능을 사용해야 할까요? (2개 선택)
✅ 정답
B. Consolidated Billing
E. Multiple AWS Accounts
💡 정답 해설
| B. Consolidated Billing | AWS Organizations 기능 중 하나로, 여러 계정을 하나의 결제 계정(Payer Account) 아래 통합하여 관리합니다. 각 부서(Linked Account)별 비용 추적 및 비용 절감(볼륨 할인) 효과를 동시에 얻을 수 있습니다. 💰 |
| E. Multiple AWS Accounts | 부서나 프로젝트별로 별도의 계정(Account) 을 생성하면, 리소스와 과금이 명확히 분리되어 Chargeback(비용 배분) 이 용이합니다. 🧩 |
❌ 오답 해설
| A. Placement groups | EC2 인스턴스 간 물리적 배치 전략(Cluster, Spread, Partition)을 지정하는 기능 | ❌ 비용이나 부서 분리와 무관 |
| C. Edge locations | CloudFront 콘텐츠 전송을 위한 전 세계 CDN 노드 | ❌ 비용 관리와 무관 |
| D. AWS Config | 리소스 구성을 추적하고 규정 준수 여부를 평가하는 서비스 | ❌ 비용 관리 목적이 아님 |
🧭 개념 요약
| AWS Organizations | 여러 AWS 계정을 중앙에서 생성·관리·통제할 수 있는 서비스 |
| Consolidated Billing | 여러 계정의 결제를 통합 관리하면서, 각 계정별로 비용 보고 및 분석 가능 |
| Linked Account 구조 | 루트 계정(Payer Account) + 부서별 연결 계정(Linked Accounts) 구성 |
| Chargeback | 실제 리소스 사용량 기반으로 부서별 비용을 내부 회계에 반영하는 절차 |
📊 시각 요약 (Mermaid)
```mermaid
flowchart TD
A["🏢 회사 계정 구조"] --> B["🧾 Payer Account<br>Consolidated Billing"]
B --> C["📂 Dept A Account<br>R&D"]
B --> D["📂 Dept B Account<br>Marketing"]
B --> E["📂 Dept C Account<br>Finance"]
B -.-> F["💰 비용 통합 관리 및 청구 보고"]
```
💬 구성 설명
- 🏢 회사 계정 구조 (Organization)
AWS Organizations 기반으로 전체 계정 구조 관리 - 🧾 Payer Account (Consolidated Billing)
모든 부서 계정의 비용을 통합 청구 및 관리 - 📂 Dept A / B / C Accounts
각 부서별로 독립적인 AWS 리소스 운영 (R&D, Marketing, Finance 등) - 💰 비용 통합 관리 및 청구 보고
비용 절감, 리소스 가시성, 예산 추적 가능
📗 한 줄 요약
부서별로 비용을 분리하려면
Multiple AWS Accounts + Consolidated Billing (AWS Organizations) 조합이 정답입니다. 🧾
📘 Q137.
Which options are AWS Cloud Adoption Framework (AWS CAF) security perspective capabilities? (Choose two)
AWS Cloud Adoption Framework(AWS CAF) 보안 관점(Security Perspective)에서 제공하는 기능은 무엇입니까?
(2개 선택)
✅ 정답
C. Incident Response
D. Infrastructure Protection
💡 정답 해설
| 선택지 | 설명 |
| C. Incident Response | 보안 사고 발생 시 감지, 대응, 복구 절차를 정의하는 능력입니다. AWS에서는 Amazon GuardDuty, AWS CloudTrail, AWS Security Hub 등을 통해 자동화된 사고 대응을 수행합니다. ⚡ |
| D. Infrastructure Protection | 네트워크, 컴퓨팅, 스토리지, 데이터 계층에서 보안 제어(방화벽, 접근 제어, 암호화 등) 를 구현하는 능력입니다. VPC 보안 그룹, WAF, Shield, NACL 등이 여기에 해당합니다. 🛡️ |
❌ 오답 해설
| 보기 | 설명 | 왜 틀렸는가 |
| A. Observability | 운영(Operations Perspective)에 속하는 개념으로, 모니터링과 로깅을 의미합니다. | ❌ 보안 관점 아님 |
| B. Incident and Problem Management | 운영(Operations Perspective) 영역에 포함됨. 문제 관리와 재발 방지 중심 | ❌ 운영 관점 |
| E. Availability and Continuity | 비즈니스 관점(Business Perspective) — 고가용성, 재해 복구 계획 수립 관련 | ❌ 보안이 아닌 비즈니스 연속성 영역 |
🧭 AWS Cloud Adoption Framework (CAF) 6 Perspectives
| Perspective | 주요 목적 | 주요 Capabilities 예시 |
| Business | 비즈니스 가치 창출, ROI 분석 | IT 재무 관리, 포트폴리오 관리 |
| People | 인재 및 조직 변화 관리 | 리더십 개발, 인재 역량 강화 |
| Governance | 위험 관리 및 규정 준수 | 비용 관리, 정책 및 표준화 |
| Platform | 기술적 기반 구축 | 인프라 자동화, 애플리케이션 포트폴리오 |
| Security | 보안, 규정 준수, 위험 완화 | Incident Response, Infrastructure Protection, Identity & Access Management, Detection |
| Operations | IT 서비스 관리 및 지속적 운영 | 모니터링, 이벤트 관리, 변경 관리 |
🧩 시각 요약 (Mermaid)
```mermaid
flowchart TD
A[🔒 AWS CAF Security Perspective] --> B[🛡️ Infrastructure Protection]
A --> C[🚨 Incident Response]
A --> D[👤 Identity & Access Management]
A --> E[🧠 Detection]
```
📗 한 줄 요약
AWS CAF의 보안(Security) 관점은 인프라 보호 + 사고 대응 중심이다.
즉, “예방(Protect) + 대응(Respond)” 이 핵심 키워드 🔐
📘 Q140.
Which AWS services can a company use to achieve a loosely coupled architecture? (Choose two)
느슨하게 결합된 아키텍처를 달성하기 위해 사용할 수 있는 AWS 서비스는 무엇입니까? (2개 선택)
✅ 정답: B. Amazon Simple Queue Service (Amazon SQS)
E. AWS Step Functions
💡 정답 해설
| 선택지 | 설명 |
| B. Amazon Simple Queue Service (SQS) | 비동기 메시지 큐 서비스로, 애플리케이션 구성 요소 간의 직접 연결을 제거하여 서비스 간 의존성을 낮추는(Decoupling) 데 핵심적입니다. 📨 |
| E. AWS Step Functions | 서버리스 워크플로우 오케스트레이션 서비스로, 여러 AWS 서비스(Lambda, ECS 등)의 실행 순서를 제어하여 느슨하게 연결된 상태로 구성요소 간 흐름을 관리할 수 있습니다. 🔄 |
❌ 오답 해설
| 보기 | 설명 | 왜 틀렸는가 |
| A. Amazon WorkSpaces | 가상 데스크톱(VDI) 서비스 | ❌ 애플리케이션 아키텍처와 무관 |
| C. Amazon Connect | 클라우드 기반 콜센터(Contact Center) 서비스 | ❌ 서비스 간 결합과 관련 없음 |
| D. AWS Trusted Advisor | 비용, 보안, 성능 등 모범 사례 점검 도구 | ❌ 아키텍처 결합도와 무관 |
🧠 핵심 개념: Loosely Coupled Architecture
| 개념 | 설명 |
| Loosely Coupled | 구성 요소들이 독립적으로 작동하여 한 부분의 오류가 전체 시스템에 영향을 주지 않음 |
| Tightly Coupled | 구성 요소가 밀접하게 연결되어 하나의 장애가 전체 시스템에 영향을 줌 |
| AWS 서비스 예시 | SQS (비동기 메시징), SNS (Publish/Subscribe), EventBridge, Step Functions 등 |
📊 시각 요약 (Mermaid)
```mermaid
flowchart LR
A["🟢 Producer Service"] -->|📤 메시지 전송| B["📦 Amazon SQS Queue"]
B -->|📥 메시지 수신| C["🔵 Consumer Service"]
C -->|🎯 오케스트레이션| D["🧩 AWS Step Functions"]
D --> E["⚙️ Lambda / ECS 등 워크로드"]
```
✅ 정답
B. Amazon Simple Queue Service (Amazon SQS)
E. AWS Step Functions
📗 한 줄 요약
SQS는 서비스 간 비동기 통신으로 결합도를 낮추고,
Step Functions는 여러 워크플로를 느슨하게 연결하여 안정적 오케스트레이션을 제공합니다. 🚀
📘 Q146.
Which option is a customer responsibility under the AWS shared responsibility model?
AWS 공동 책임 모델에서 고객의 책임에 해당하는 것은 무엇입니까?
✅ 정답: B. Application data security
💡 정답 해설
AWS와 고객은 각각 클라우드 보안의 다른 측면을 책임집니다.
이를 “Security of the Cloud” (AWS의 책임) vs “Security in the Cloud” (고객의 책임) 으로 구분합니다.
| 구분 | 설명 | 책임 주체 |
| Security of the Cloud | AWS가 클라우드 인프라 자체의 보안을 관리함 (데이터센터, 하드웨어, 네트워크 등) | 🟦 AWS |
| Security in the Cloud | 고객이 클라우드 위에 배포하는 데이터, 애플리케이션, OS 보안 등을 관리함 | 🟩 고객 |
🔍 고객 책임 예시 (Security in the Cloud)
- 애플리케이션 및 데이터 암호화
- 사용자 접근 제어 (IAM)
- OS 보안 패치
- 네트워크 ACL / 보안 그룹 설정
- 로깅 및 모니터링 구성 (CloudTrail, Config 등)
🔒 AWS 책임 예시 (Security of the Cloud)
- 물리적 데이터센터 보안 (CCTV, 출입통제 등)
- 하이퍼바이저, 호스트 서버, 네트워크 인프라
- 하드웨어 유지보수 및 패치
- 글로벌 인프라 가용성 및 탄력성 확보
❌ 오답 해설
| 보기 | 설명 | 이유 |
| A. Maintenance of underlying hardware of Amazon EC2 instances | 물리적 서버 유지보수 | ❌ AWS의 책임 |
| C. Physical security of data centers | 데이터센터 접근 제어, 전력, 냉각 등 물리적 인프라 보안 | ❌ AWS의 책임 |
| D. Maintenance of VPC components | VPC는 고객이 구성하지만, 기본 인프라는 AWS가 관리 | ❌ VPC 인프라 자체는 AWS 관리, 단 설정은 고객이 관리 |
📊 시각 요약 (Mermaid)
```mermaid
flowchart LR
A[AWS 책임] --> B[🔒 Security of the Cloud<br>물리적 인프라, 네트워크, 하드웨어]
A2[고객 책임] --> C[🧩 Security in the Cloud<br>데이터, 애플리케이션, IAM, 암호화]
```
📗 한 줄 요약
AWS는 클라우드 자체를 보호(Security of the Cloud),
고객은 클라우드 내 자산을 보호(Security in the Cloud) 한다. 💡
'AWS > AWS CLF-C02' 카테고리의 다른 글
| [AWS CLF-C02] Q251 ~ Q300 오답노트 2EA (0) | 2025.10.16 |
|---|---|
| [AWS CLF-C02] Q201 ~ Q250 오답노트 10EA (0) | 2025.10.14 |
| [AWS CLF-C02] Q151 ~ Q200 오답노트 7EA (0) | 2025.10.14 |
| [AWS CLF-C02] Q051 ~ Q100 오답노트 5EA (0) | 2025.10.09 |
| [AWS CLF-C02] Q001 ~ Q050 오답노트 6EA (0) | 2025.10.09 |