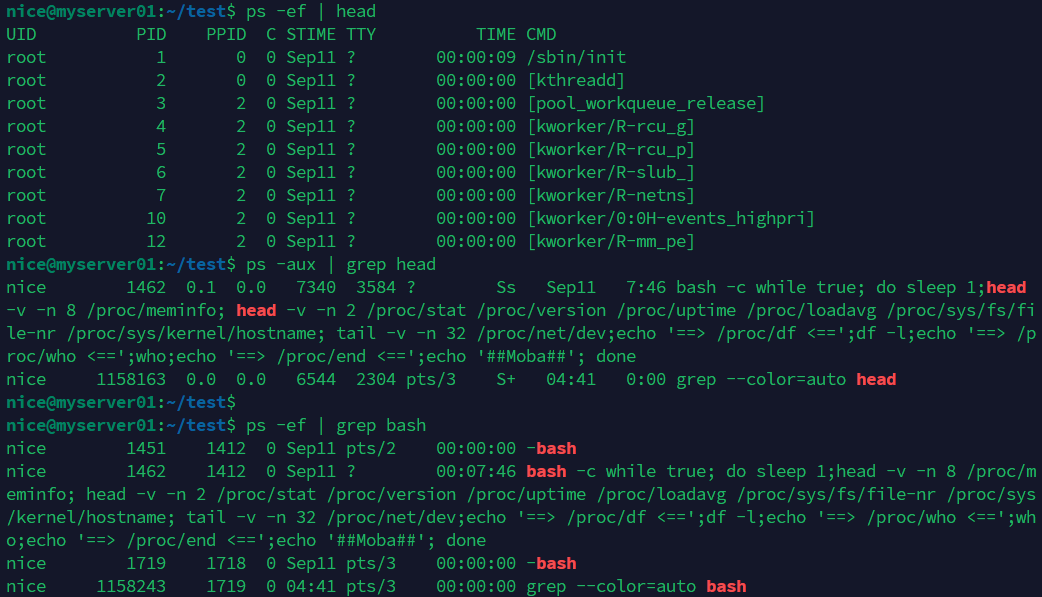
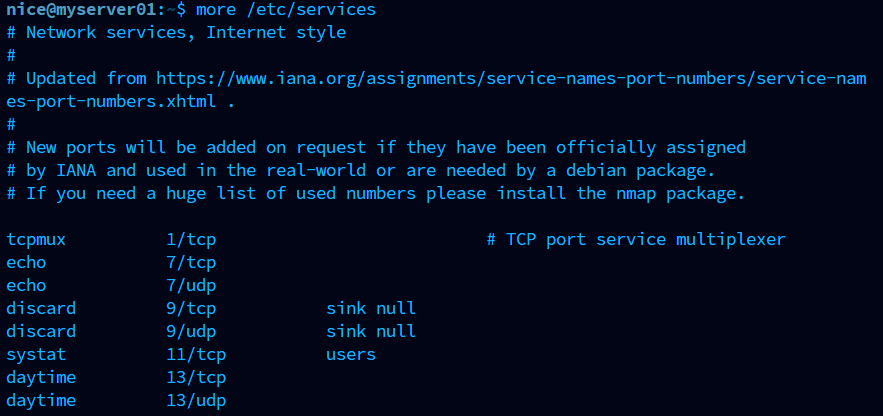
$ ls -l
-rw-r--r-- 1 user group 120 Sep 15 10:00 test.txt
# - → 파일 종류(-=일반 파일, d=디렉토리)
# rw- → 소유자(user)는 읽기/쓰기 가능
# r-- → 그룹(group)은 읽기만 가능
# r-- → 기타(other)는 읽기만 가능
# user → 소유자 이름
# group → 그룹 이름
# 120 → 파일 크기(바이트)
# Sep 15 ... → 최종 수정 시간
# test.txt → 파일 이름
👉 즉, rw-r--r-- 는 소유자는 읽기/쓰기, 그룹과 기타는 읽기만 가능하다는 의미예요.
flowchart TD
A[소유자 user] -->|r=4| R1[읽기]
A -->|w=2| W1[쓰기]
A -->|x=1| X1[실행]
B[그룹 group] --> R2[읽기]
B --> W2[쓰기]
B --> X2[실행]
C[기타 other] --> R3[읽기]
C --> W3[쓰기]
C --> X3[실행]
3️⃣ 기본 권한과 umask
파일 생성 시 기본 권한:
일반 파일: 664 → rw-rw-r--
디렉토리: 775 → rwxrwxr-x
umask: “빠지는 권한”을 의미 (즉, 허용하지 않을 권한을 지정)
umask # 현재 값 확인 (보통 0002)
umask -S # 문자 방식으로 확인 (u=rwx,g=rwx,o=rx)
umask 077 # 다른 사용자 권한 모두 차단
touch private.txt
ls -l private.txt
# 결과: -rw------- (소유자만 접근 가능)
4️⃣ 특수 권한 (SetUID, SetGID, Sticky Bit)
권한을 4자리로 표기할 때 앞자리가 특수 권한
4xxx → SetUID
2xxx → SetGID
1xxx → Sticky Bit
chmod 4755 program # SetUID 적용 (소유자 권한으로 실행)
chmod 2755 project # SetGID 적용 (그룹 권한 상속)
chmod 1777 /tmp # Sticky Bit 적용 (본인만 삭제 가능)
예시:
ls -l /usr/bin/passwd
-rwsr-xr-x 1 root root ... passwd
# s → root 권한으로 실행됨 (SetUID)
ls -ld /tmp
drwxrwxrwt 14 root root ... tmp
# t → sticky bit (다른 사람 파일은 못 지움)
5️⃣ 실습 순서
ls -l test.txt → 권한 확인
chmod g+x test.txt → 그룹 실행 권한 추가
chmod u-w test.txt → 소유자 쓰기 제거
chmod 700 test.txt → 결과 -rwx------
umask → 현재 값 확인
ls -l test.txt → 변경 확인
umask 077 → 보안 강화
touch private.txt && ls -l private.txt → -rw------- 생성 확인
6️⃣ 현업에서 자주 쓰는 권한 설정 🔑
웹 서버 로그 디렉토리: chmod 750 /var/log/httpd → 관리자와 웹서버 그룹만 접근 가능
/tmp 디렉토리: 항상 1777 (rwxrwxrwt) → 누구나 파일 만들 수 있지만 자기 것만 삭제 가능
개인 키 파일 (~/.ssh/id_rsa): chmod 600 → 오너만 읽고 쓸 수 있어야 함 (보안 필수)
공유 프로젝트 디렉토리: chmod 2775 project → 새 파일이 자동으로 그룹 소유 상속(SetGID)
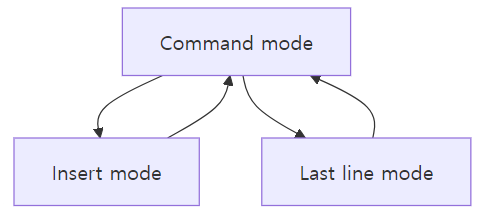
graph TD A[명령 모드 (Command mode)] --> B[입력 모드 (Insert mode)] A --> C[마지막 행 모드 (Last line mode)] B --> A C --> A
```
명령 모드: vi 실행 시 기본 모드 (복사, 삭제, 이동 등 명령어 실행)
입력 모드: 글자를 입력하는 모드 (i, a, o 로 진입)
마지막 행 모드: 저장·종료·검색 같은 명령 입력 (:wq, :q!)
2. 자주 쓰는 기본 명령어
동작명령
입력 시작
i (커서 앞), a (커서 뒤), o (새 줄)
저장 & 종료
:wq
강제 종료 (저장 안 함)
:q!
이동
h(왼쪽), l(오른쪽), j(아래), k(위), :10(10번 줄 이동), G(파일 끝)
삭제
dd (한 줄 잘라내기)
복사 & 붙여넣기
yy (복사), p (붙여넣기)
검색
/문자열
3. 문서 편집기 실습
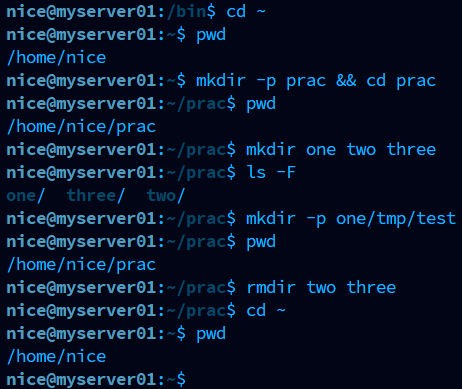
① 연습용 파일 생성
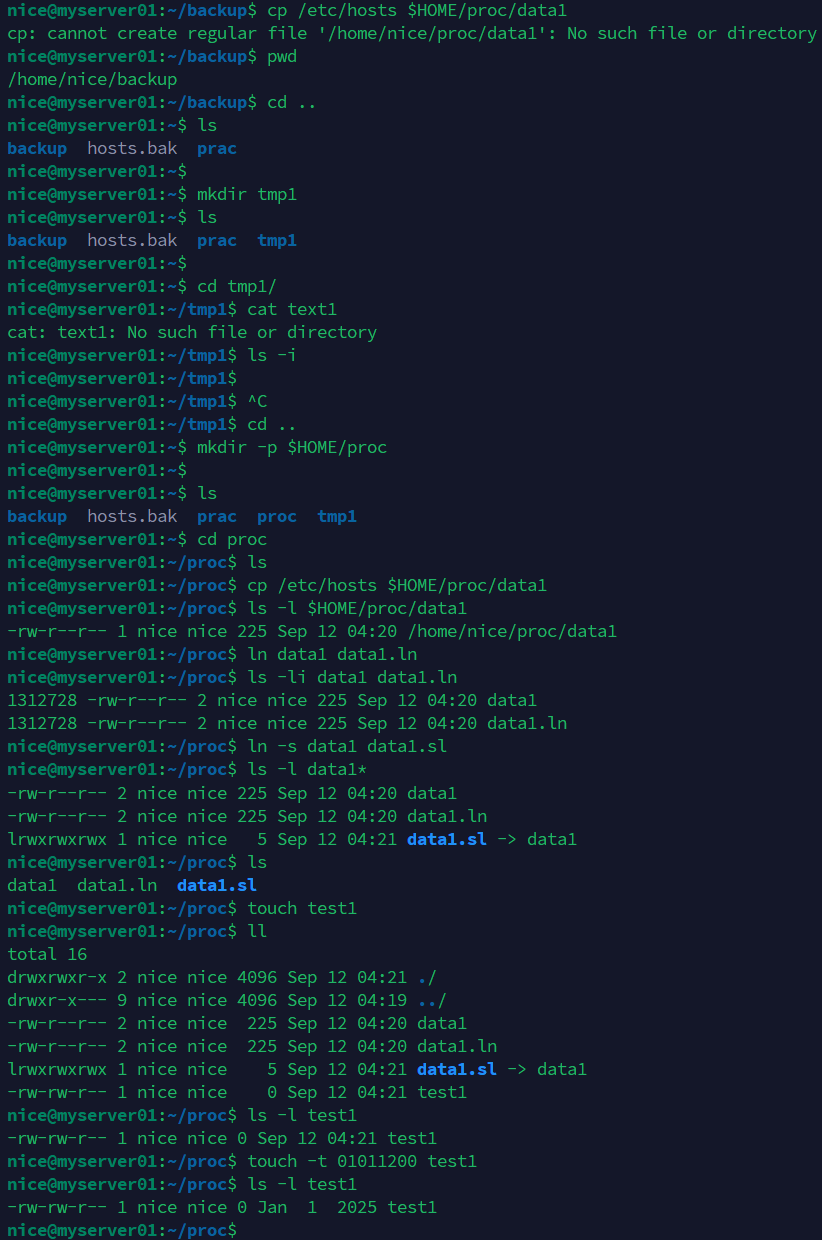
cd$HOME/proc # 실습 디렉토리로 이동 vi test.txt # vi 편집기 실행
입력 예시 (입력 모드에서 붙여넣기):
Welcome to vi editor practice This is a sample text file You can edit this file using vi Let's learn some basic commands The /etc/hosts file is important Try searching for the word hosts Delete this line and paste it below Endof the practice file
② 파일 내용 확인
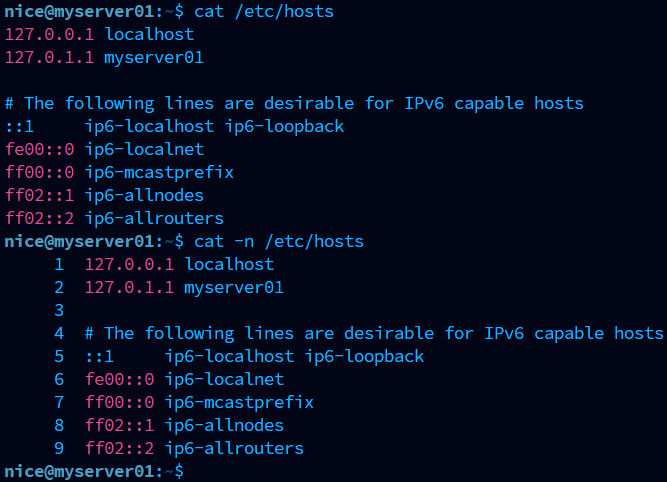
cat test.txt # 파일 전체 내용 출력
👉 cat은 파일 내용을 한 번에 보여줍니다.
③ 줄 번호 표시 & 특정 줄로 이동
:5 # vi에서 5번째 줄로 이동
👉 .exrc 설정에서 set nu를 추가하면 항상 줄 번호가 표시됩니다.
④ 삭제 & 붙여넣기
dd# 현재 줄 삭제 (잘라내기) p # 바로 아래 줄에 붙여넣기
⑤ 문자열 검색
/file # "file" 이라는 단어 검색
👉 / 입력 후 검색어 입력 → 해당 단어로 커서 이동
⑥ 저장 & 종료
:wq # 저장 후 종료 :q! # 저장하지 않고 강제 종료
⑦ .exrc 설정 파일 다루기
ls -a | grep exrc # .exrc 파일 존재 여부 확인mv .exrc .exrc.bak 2>/dev/null # 있으면 백업 vi .exrc # 새 설정 파일 생성
입력할 내용 (vi 설정):
set nu " 줄 번호 표시 set ignorecase " 검색 시 대소문자 무시 set autoindent " 자동 들여쓰기 set showmode " 현재 모드 표시 (--INSERT-- 등)
👉 저장 후 종료 (:wq)
⑧ 설정 적용 & 확인
vi ~/prac/test.txt
줄 번호 확인 (set nu)
/hosts 검색 시 대소문자 무시되는지 확인 (set ignorecase)
새 줄 입력 시 자동 들여쓰기 되는지 확인 (set autoindent)
모드 표시 확인 (--INSERT-- 뜨는지 확인, set showmode)
4. 한 줄 한 줄 주석 설명
cat test.txt # 파일 내용을 터미널에 출력 :5 # vi 안에서 5번째 줄로 이동dd# 현재 줄 잘라내기 p # 잘라낸 줄을 현재 커서 아래에 붙여넣기 /file # "file" 문자열 검색 :wq # 저장 후 종료
5. 현업에서 자주 쓰는 vi 활용 ✨
서버 설정 파일 편집: /etc/nginx/nginx.conf, /etc/hosts 같은 시스템 설정
로그 파일 빠른 수정: 긴 로그 파일에서 특정 키워드 검색 (/error)
빠른 줄 이동: 에러 로그에서 특정 줄 번호 확인 후 :숫자로 이동
복사/붙여넣기: 설정 블록을 잘라내어 다른 위치에 붙여넣을 때 yy, p 자주 사용
.exrc 자동 설정: 항상 줄 번호 표시, 검색 시 대소문자 무시, 자동 들여쓰기 → 현업 엔지니어들이 꼭 켜두는 옵션
.exrc 자동 설정 방법
vi ~/.exrc
set nu " 줄 번호 표시 set ignorecase " 검색 시 대소문자 구분 안 함 set autoindent " 자동 들여쓰기 set showmode " 현재 모드 표시 (--INSERT-- 같은 상태 표시)
회사 애플리케이션: Elastic Load Balancer (ELB) 뒤의 EC2 Auto Scaling 그룹에서 실행
평상시에는 성능 안정적
하지만 트래픽이 증가하면 매일 동일한 4시간 동안 성능 저하 발생
👉 이 문제를 해결할 수 있는 가장 효율적인 방법은?
🔹 선택지 분석
A. 가중치 라우팅 정책 사용 + 두 번째 ELB 구성 → 불필요하게 복잡하며 문제의 원인(트래픽 피크 시간 성능 저하) 해결에 맞지 않음 ❌
B. 더 큰 인스턴스 유형 사용 → 성능 개선 가능하지만, 특정 시간대만 부하가 증가하므로 비용 낭비 ❌
C. EC2 인스턴스 수를 예약 조정 작업(Scheduled Scaling)으로 확장 → ✅ 정답 → 트래픽 증가 시간이 예측 가능(매일 동일 4시간)하므로 예약된 스케일링으로 미리 인스턴스 확장 가능
D. 수동으로 EC2 인스턴스 추가 → 관리 부담 크고 자동화되지 않음 ❌
✅ 정답: C
📝 쉬운 해설
Auto Scaling은 2가지 방식으로 동작:
동적 스케일링 → CloudWatch 지표 기반 (예: CPU > 70%)
예약 스케일링 → 트래픽 피크 시간이 미리 예측 가능할 때 사용
이 문제는 “매일 같은 시간에 성능 저하” → 예약 스케일링(Scheduled Scaling)이 정답
📊 Mermaid 시각화
```mermaid
flowchart TD Users[사용자 트래픽] --> ELB[Elastic Load Balancer] ELB --> ASG[Auto Scaling 그룹] ASG --> EC2[EC2 인스턴스] Schedule[예약 스케일링: 매일 동일 시간 인스턴스 확장] --> ASG
```
🎯 암기 팁
👉 “매일 같은 시간대 트래픽 증가 = Scheduled Scaling”
예측 불가 = 동적 스케일링
예측 가능 = 예약 스케일링
📘 Q113 문제 정리
🔹 문제 요약
회사는 단일 리전의 EC2 인스턴스에서 애플리케이션을 호스팅
애플리케이션은 HTTP가 아닌 TCP 트래픽 지원 필요
AWS 네트워크를 활용해 짧은 지연 시간으로 콘텐츠 제공 원함
Auto Scaling 그룹과 탄력적 로드 밸런싱도 필요
👉 어떤 아키텍처가 요구사항을 충족할까?
🔹 선택지 분석
A. ALB + CloudFront → ALB는 HTTP/HTTPS 레벨 7 전용, TCP 지원 불가 ❌
B. ALB + Global Accelerator → Global Accelerator는 ALB를 엔드포인트로 지원하지만, TCP/UDP 지원을 위해서는 NLB 사용이 더 적합 ❌
C. NLB + CloudFront → CloudFront는 HTTP/HTTPS 캐싱 전용 서비스, TCP 트래픽 가속화는 불가 ❌
D. NLB + Global Accelerator → NLB는 TCP/UDP 레벨 4 로드 밸런싱 지원 ✅ → Global Accelerator는 AWS 글로벌 네트워크를 통해 최적화된 경로와 낮은 지연 시간 제공 ✅ → Auto Scaling 그룹 뒤에 NLB 연결 가능 ✅
✅ 정답: D
📝 쉬운 해설
ALB (Application Load Balancer) = HTTP/HTTPS (L7) 전용
NLB (Network Load Balancer) = TCP/UDP (L4) 지원 → 문제 조건 충족
CloudFront = 콘텐츠 캐싱/CDN, TCP 가속 목적과는 맞지 않음
Global Accelerator = 전 세계 엣지 로케이션을 활용한 네트워크 최적화 → 짧은 지연 시간 보장
즉, TCP 기반 애플리케이션 + 글로벌 저지연 = NLB + Global Accelerator 조합이 정답입니다.
📊 Mermaid 시각화
```mermaid
flowchart TD Users[사용자 트래픽] --> ELB[Elastic Load Balancer] ELB --> ASG[Auto Scaling 그룹] ASG --> EC2[EC2 인스턴스] Schedule[예약 스케일링: 매일 동일 시간 인스턴스 확장] --> ASG
```
🎯 암기 팁
👉 “TCP/UDP 필요 = NLB, 글로벌 저지연 = Global Accelerator”
👉 “지표 기반 자동조치 = CloudWatch Alarm + EC2 Action” 스크립트/Run Command ❌, 에이전트 ❌. 기본 CPU 지표로 충분 ✅
“지표 기반 자동 조치 = CloudWatch Alarm + EC2 Action(Stop/Terminate)”
운영 시 주의사항
Auto Scaling 그룹인지 여부 확인
개별 인스턴스에 “Terminate”를 걸면 ASG가 다시 인스턴스를 띄울 수 있음.
ASG 환경이라면: Target Tracking/Step Scaling(예: 평균 CPU 10% 유지)으로 스케일-인이 더 자연스러움.
Stop vs Terminate
Stop: 재시작 가능(요금: EBS 스토리지만).
Terminate: 완전 삭제(스냅샷/백업 전략 사전 점검 필수).
지표 지연: CloudWatch 표준 지표는 수 분 지연될 수 있음 → 서비스 특성에 맞게 Period/Evaluation 조정.
한 줄 정리
“지표 기반 자동종료 = CloudWatch Alarm(평균 CPU 60분 <10%) + EC2 Action(Stop/Terminate)”
📘 Q138 문제 정리
📝 문제
회사는 ALB(Elastic Load Balancer) 뒤의 EC2 웹 애플리케이션을 운영 중
보안팀은 AWS Certificate Manager(ACM) SSL 인증서를 사용하여 웹 사이트를 보호하려고 함
요구사항: 모든 HTTP 요청을 HTTPS로 자동 리디렉션해야 한다
✅ 보기
A. ALB에 HTTPS 리스너(포트 80)만 두고 SSL 인증서를 연결 → ❌ (포트 80은 HTTP 전용, HTTPS 리스너는 443 필요) B. ALB에 포트 80 HTTP 리스너와 포트 443 HTTPS 리스너를 두고, SSL 인증서를 포트 443에 연결 + 포트 80 요청은 443으로 리디렉션 규칙 설정 → ✅ C. ALB에 두 개의 **TCP 리스너(80, 443)**를 두고 SSL 인증서를 443에 연결 → ❌ (TCP는 SSL/TLS 오프로딩 지원 불가) D. NLB에 두 개의 TCP 리스너를 두고 SSL 인증서를 443에 연결 → ❌ (NLB는 HTTP → HTTPS 리디렉션 기능 없음)
🎯 정답
B. 포트 80 HTTP 리스너 + 포트 443 HTTPS 리스너 구성, 80 → 443 리디렉션 규칙 적용
💡 해설
HTTP → HTTPS 강제 리디렉션은 Application Load Balancer에서 가능
ALB 리스너 규칙에서 리디렉션(redirect action) 기능 제공
**NLB(Network Load Balancer)**는 단순 TCP 수준 로드밸런싱이라 이런 기능 없음
NLB는 Layer 4, ALB는 Layer 7 → 리디렉션 같은 고급 기능은 ALB에서만 가능
📘 Q140 문제 정리 (Amazon ECS 네트워크 트래픽 모니터링)
❓ 문제
회사는 Amazon ECS (Elastic Container Service) 를 사용해 Amazon EC2 인스턴스에서 컨테이너화된 애플리케이션을 실행 중입니다. SysOps 관리자는 ECS 작업 간 트래픽 흐름만 모니터링해야 합니다.
👉 어떤 단계 조합을 수행해야 할까요? (2개 선택)
✅ 정답: B, C
B. 각 작업의 탄력적 네트워크 인터페이스에서 VPC 흐름 로그를 구성한다. → VPC Flow Logs는 네트워크 트래픽을 캡처해 CloudWatch Logs나 S3에 저장할 수 있음. → ECS 작업 간의 트래픽을 확인하려면 ENI(Elastic Network Interface) 레벨에서 Flow Logs를 활성화해야 함.
C. 작업 정의에서 awsvpc 네트워크 모드를 지정한다. → awsvpc 모드는 각 ECS Task에 자체 ENI를 부여하여 VPC 네트워크와 직접 통신할 수 있게 함. → 따라서 작업(Task) 단위로 네트워크 트래픽 모니터링이 가능해짐.
❌ 오답 해설
A. CloudWatch Logs 구성 → 애플리케이션 로그 수집 용도이지, 네트워크 트래픽 흐름 모니터링은 불가능.
D. 브리지(bridge) 네트워크 모드 → 컨테이너 인스턴스 내에서 Docker 가상 네트워크를 사용, ENI 단위 추적 불가.
E. 호스트(host) 네트워크 모드 → 컨테이너가 EC2 인스턴스의 네트워크 스택을 공유, 개별 Task 네트워크 추적 불가.